On May 5th, 2024, Rand Fishkin (the founder of Moz) received an email from someone claiming to have access to documentation from Google’s internal Content Warehouse API. Based on the document’s commit history, it was uploaded to a public GitHub repository on March 27 and stayed there until May 7, 2024.
Soon after, on May 27th, Rand Fishkin (now the cofounder of SparkToro) and Mike King of iPullRank published a couple of super in-depth articles that reveal and dive deep into what these anonymous parties shared with them.
This shook up the SEO world, sparking conversations left, right, and center on the social web (LinkedIn, X, blog articles, etc.) about how our understanding of SEO may be skewed due to misleading public statements from Google spokesmen over the years.
To give you a quick overview, the leaked documents shed light on the realities that Google harnesses clickstream data, data from the Chrome browser, and a variety of ranking factors such as site authority, user interactions (including NavBoost), and feedback from quality raters.
In this post, we’ll list out the confirmed Google ranking factors that this leak has brought to light. This can help you tailor your future content strategy for maximum impact.
What the Google API Leak Reveals About Ranking
The biggest takeaway from this leak is bluntly simple: you can’t trust Google’s spokesman. Over the years, they’ve made multiple public statements that contradict what the leaked documents suggest. For example, Google consistently denied using click-based user signals as ranking factors, asserted that subdomains are not evaluated individually, refuted the existence of a sandbox for new websites, denied the significance of domain age, among other things.
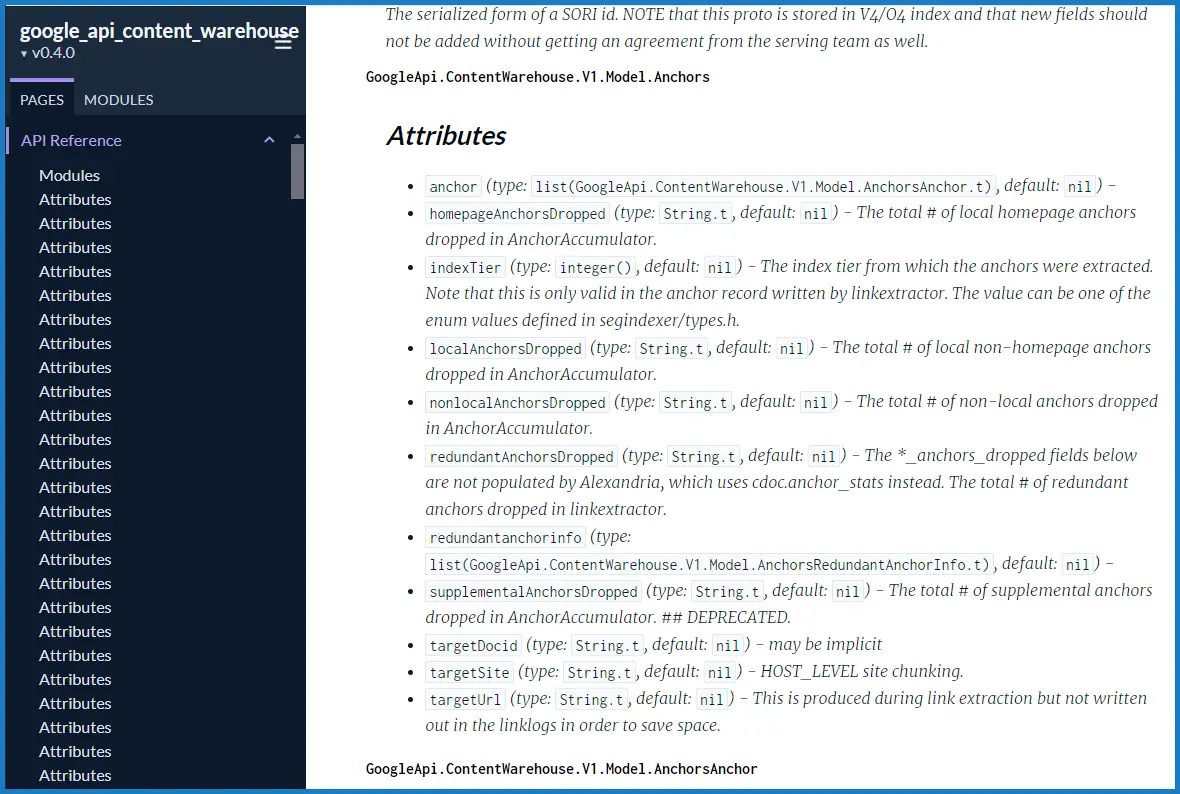
During a conversation with Erfan Azimi (the confidential informant), an SEO expert and the founder of a digital agency, Erfan revealed to Rand the contents of the leak: more than 2,500 pages of API documentation encompassing 14,014 attributes (API features) purportedly from Google’s internal Content API Warehouse.
While this documentation does not reveal the specific weights of different confirmed Google ranking signals in the algorithm or establish which elements are directly used in rankings, it does offer granular details on the data Google gathers, which is presumably utilized for ranking websites.
Speaking of rankings, we as an experienced SaaS content marketing agency now have an even better clarity about which aspects Google does consider in ranking websites.
Confirmed Google Ranking Factors based on Google API Leak
Thanks to this leak, we can remove some of the guesswork in our SEO content strategy. Let’s list out the confirmed Google ranking factors, or rather elements, that we as search marketers should focus on going forward.
1. Click Data
The documents indicate that user interaction signals, particularly click data, greatly influence rankings. The NavBoost system employs clickstream data to rank pages according to user behavior, favoring sites with greater engagement.
The documentation specifically references features such as “goodClicks,” “badClicks,” and “lastLongestClicks,” which are associated with NavBoost and Glue.
This data includes user interactions with search results, such as click-through rates (CTR), bounce rates, and the amount of time users spend on a page.
Google’s NavBoost system explicitly uses click data to modify rankings based on user behavior. Pages that engage users more effectively are deemed more relevant and, therefore, receive higher rankings. This method strives to boost user satisfaction by prioritizing content that meets user intent and maintains interest.
2. Chrome Data
The leaked documents show that data from the Chrome browser influences search rankings. Despite previous denials, with Matt Cutts stating that Google does not use Chrome data for rankings and John Mueller recently reaffirming this claim, it is evident that site-level views data from Chrome is utilized to refine and enhance Google’s algorithms.
According to the documents, Chrome monitors user interactions such as time on a page, clicks, and browsing patterns. This information enables Google to gauge user preferences and behavior, allowing them to rank pages based on actual usage. Metrics like bounce rate, session duration, and scroll depth, gathered through Chrome, offer insights into user experience and content quality.
Additionally, a metric known as “topURL”—the most clicked page according to Chrome data—is also used in ranking decisions.
By incorporating data from Chrome, Google is better positioned to evaluate the relevance and quality of a webpage, ensuring that pages with higher engagement receive improved rankings.
3. Website Authority
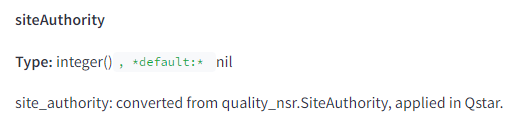
Google search API leak has verified Google’s use of a “siteAuthority” metric, which evaluates the overall trust and authority of a website. This contradicts Google’s public statements denying the use of domain authority, indicating that websites with higher authority typically fare better in search rankings.
The concept of site authority is a crucial ranking factor in Google’s algorithm, similar to the often-discussed but officially denied “domain authority” (a metric developed by Moz). It measures a website’s overall trustworthiness and credibility. Factors that contribute to site authority include the quality and relevance of content, the backlink profile, and the historical performance of the site.
A higher site authority increases a website’s likelihood of ranking well in search results. This metric is fundamental to Google’s strategy to prioritize reliable sources, ensuring its users get correct information.
For example, a site that features comprehensive content from subject matter experts and a robust backlink profile from reputable sources will achieve a higher site authority score than a newer or less established site. This enables Google to limit the spread of misinformation by favoring sites that have consistently demonstrated reliability.
4. Sandboxing
The leaked Google documents have exposed the “sandbox effect,” a phenomenon where new websites temporarily face suppressed search rankings despite having quality content and solid SEO practices. This period is commonly known as the “sandbox” because new sites are essentially placed in a holding pattern until they demonstrate consistent reliability and trustworthiness. Essentially, the age of the domain plays a crucial role in Google’s ranking decisions.
This is regulated through the “hostAge” attribute, which influences how quickly new sites can ascend in rankings. It takes into account both the age of the domain and the website itself. Google implements this period to verify that new sites are not spammy and are capable of providing consistent, valuable content to users.
5. Backlinks and Anchors
Links continue to be a crucial ranking factor. Relevant backlinks from reputable sources are a big boost to a site’s search performance.
The Google search API leak shed light on several ways links impact rankings:
Quality: Google prioritizes links from credible sources rather than a large volume of low-quality links.
Relevance: Links placed within relevant, high-quality content are more influential than those in unrelated or low-quality environments.
Anchor: The clickable text in a link, or anchor text, provides context about the content of the linked page. Descriptive anchor text strengthens a page’s relevance signals, aiding its ranking for specific keywords.
Moreover, incorporating target keywords in anchor text can boost a page’s relevance for those terms. However, over-optimization or excessive use of exact-match keywords can trigger penalties. Anchor text should be naturally woven into the content, ensuring a smooth reading experience without appearing forced or spammy. Employ a mix of exact-match, partial-match, branded, and generic anchor text to maintain a natural link profile.
6. Content Originality and Quality
Quality content is still and will always stay at the core of effective SEO.
Yet, nuances from the leaked documents offer additional insights. First, short content can be as effective as long-form content if it provides original insights. The “OriginalContentScore” metric indicates that short content is evaluated for its originality. Therefore, the issue with thin content isn’t necessarily about length.
Second, Google measures the number of tokens and the ratio of total words in the body to the number of unique tokens. The documents suggest there is a maximum token count considered for a document, highlighting the importance of placing your most critical content early in the text.
Lastly, Google tracks the average weighted font size of terms within documents, and this metric also applies to the anchor text of links. This suggests that the prominence of text, both in terms of content and links, plays a role in how content is evaluated.
Besides, remember the Panda update?
Judging from the leaked Google documents, the Panda algorithm tracks down low-quality content to ensure users receive valuable information. It evaluates websites for issues such as thin content, duplicate content, and overall quality, and its impact can extend to entire sites (not just individual pages).
Panda employs a range of quality signals stored in Google’s databases to assess and rank content. User engagement data, such as long clicks and bounce rates, play a significant role. The former indicates valuable content whereas the latter suggests low-quality content. If a site harbors a lot of low-quality content, it can mean a demotion in its overall search rankings.
7. Topicality Score
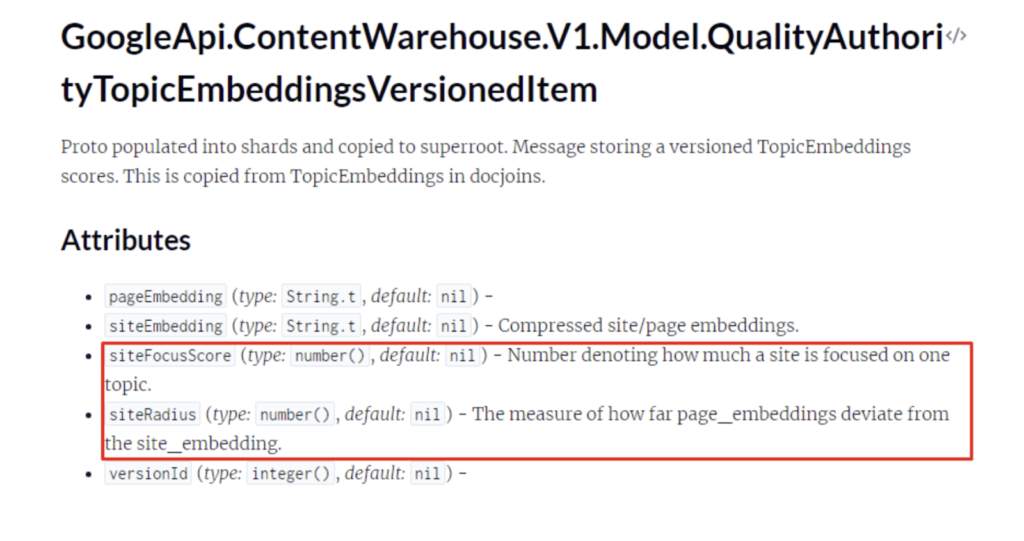
Considering the leaked documents, Google appears to be vectorizing pages and entire websites, comparing page embeddings and content against site embeddings to assess how off-topic a page may be.
The “siteFocusScore” evaluates how closely a site adheres to a single topic, while the “siteRadius” measures the degree to which a page deviates from the core topic based on the “site2vec” vectors created for the site.
So essentially, the score assesses a site’s relevance to specific topics. High topicality scores — also known as topical authority — can enhance a site’s rankings for queries related to its primary topics. Sites with content that deeply focuses on specific topics should receive higher scores for those topics.
8. Page Updates
Another critical insight from the Google API leak is that content that is not regularly updated receives the lowest storage priority from Google, making it less likely to appear in search results for queries that demand fresh content.
By storage priority, Google categorizes content storage as follows:
Flash Drives: Used for the most important and frequently updated content.
Solid State Drives: Used for less critical content.
Standard Hard Drives: Used for content that is seldom updated.
Moreover, Google uses a metric called “pageQuality” and employs a Large Language Model (LLM) to estimate “effort” for article pages. This metric might help Google determine the ease with which a page could be replicated. Unique images, videos, embedded tools, and in-depth content can boost your score on this metric.
Additionally, the leaked information reveals that Google maintains a record of every version of a web page, essentially creating an internal Web Archive. However, Google only uses the last 20 versions of a document. The documents differentiate between a “Significant Update” and a “Update,” though it’s still not clear if significant updates are essential for this version management strategy.
9. Page Titles
The documents reveal the existence of a “titlematchScore,” indicating that Google continues to place significant emphasis on how closely a page title matches a search query.
Gary Ilyes has pointed out that the notion of an optimal character count for metadata is a myth propagated by SEOs. The dataset doesn’t include any metrics that measure the length of page titles or snippets. The only character count measure mentioned in the documentation is “snippetPrefixCharCount,” which determines what can be used as part of the snippet.
This enhances our understanding that while lengthy page titles might not be ideal for generating clicks, they can still positively influence rankings.
10. Onsite Prominence
“OnSiteProminence” is a metric used to evaluate the significance of a document within a website. It is determined by simulating traffic flow from the homepage and other high-traffic pages, which are referred to as “high craps click pages.”
This metric primarily assesses internal link scores, gauging how prominently a page is featured within the site’s internal linking structure. The more links a page receives from important pages (such as the homepage), the higher its OnSiteProminence score. Google employs simulated traffic to estimate how frequently users might navigate to a page from key entry points on the site.
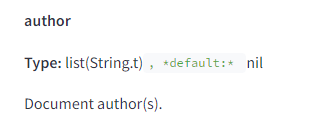
11. Authors
The documents reveal that Google explicitly stores author information, underscoring the importance of authorship in its ranking processes.
As highlighted in Mike’s article, the leaked documents indicate that Google recognizes authors and treats them as entities within its system. Therefore, building an online presence and establishing yourself as a credible author could lead to ranking advantages.
That being said, the precise influence of “E-E-A-T” (Experience, Expertise, Authoritativeness, Trustworthiness) on rankings is still a topic of debate. E-E-A-T might be more of a marketing concept than a substantial factor, as several high-ranking brands do not necessarily demonstrate significant experience or trustworthiness.
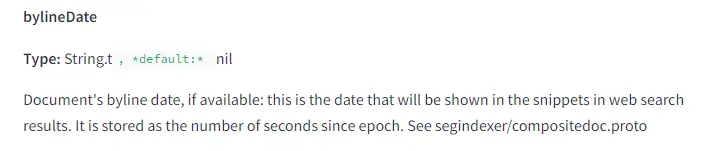
12. Byline Date
Google aims to provide fresh content, and the documents highlight the importance of associating dates with pages, including “bylineDate,” “syntacticDate,” and “semanticDate.”
13. Location
According to the documents, Google tries to link pages with specific geographic locations and ranks them accordingly. Thus, a page’s geographic location significantly impacts search results, with local SEO practices enhancing site rankings in particular regions. Local relevance and proximity are crucial for local search rankings.
NavBoost geo-fences click data, analyzing it at the country and state/province levels, as well as differentiating between mobile and desktop usage. However, if Google lacks sufficient data for certain regions or user-agents, it might apply this localization broadly across all query results.
In simpler terms, Google prioritizes local businesses and content that are geographically relevant to the user’s location. Search results are customized to showcase businesses, services, and information nearest to the user’s current location. Pages that specifically cater to local needs or interests tend to perform better in rankings.
14. Demotions
Certain practices or types of content can lead to ranking demotions. In addition to the demotion due to the Panda algorithm, here are several more algorithmic demotions to consider for your content strategy:
Anchor Mismatch: Links that do not align with their target site are demoted for lack of relevance.
SERP Demotion: Pages are demoted based on negative signals from search results, which may be due to low click rates.
Nav Demotion: Poor navigation or user experience can lead to a demotion.
Exact Match Domains Demotion: There has been a reduced value for exact match domains since 2012.
Product Review Demotion: This is likely linked to recent updates targeting low-quality reviews.
Location Demotions: Global pages may be demoted in favor of location-specific relevance.
Porn Demotions: These are category-specific demotions.
Other Link Demotions: There are additional penalties based on link practices.
These demotions underscore the importance of producing high-quality content, ensuring a great UX, and following ethical SEO practices.
15. Entities
In the context of SEO and Google’s algorithms, an entity refers to a distinct, well-defined subject such as a person, place, organization, concept, or thing. Entities are recognized based on their unique characteristics and relationships with other entities. They are used by search engines to understand the context and meaning of content, helping to improve search accuracy and relevance.
By focusing on entities, search engines can better match search queries with the most relevant and authoritative content.
The “RepositoryWebrefDetailedEntityScores” model in the Google API Content Warehouse documentation describes attributes that measure various aspects of entities within a document. Key attributes include:
Connectedness: How related the entity is to other entities in the document.
DocScore: A score that ranks the document’s relevance to the entity.
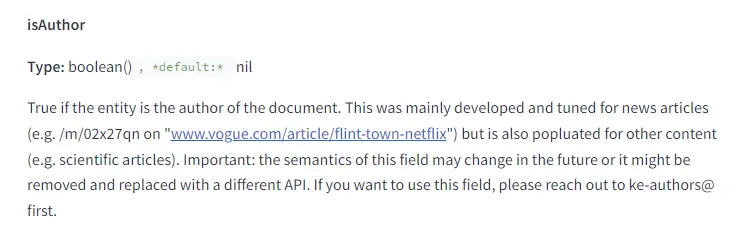
IsAuthor and IsPublisher: Boolean values identifying if the entity is the author or publisher.
NormalizedTopicality: A normalized score representing how much of the document discusses the entity.
RelevanceScore: A machine-learning-generated score indicating the entity’s relevance.
These attributes are crucial for understanding how Google assesses and utilizes entity information within documents.
How the Google API Leak Should Inform Your Content Strategy
Based on all the elements discussed above, here are the action areas to focus on in your SEO content strategy:
Optimizing for click data means crafting engaging meta descriptions and titles to enhance CTR, providing engaging and relevant content to lower bounce rates, and improving the page experience to extend dwell time. These tactics signal to Google that the content is valuable and pertinent, potentially leading to improved search rankings.
Concentrate on improving the UX by enhancing page load times, navigation, and content engagement. Develop interactive content, clear calls-to-action, and visually appealing designs. Employ tools such as Hotjar to monitor and analyze user behavior on your website and pinpoint areas that need improvement.
Although the specific metrics and algorithms defining site authority are proprietary, you should concentrate on creating high-quality content, securing reputable backlinks, and ensuring a consistent, positive user experience to boost your site’s authority and, consequently, its search engine rankings.
Realistically, there’s limited action you can take regarding sandboxing. Patience is key. Focus on consistently delivering high-quality content. Additionally, during this period, it’s beneficial to enhance the site’s authority with quality backlinks. Continue tracking performance metrics and optimizing the site, recognizing that ranking improvements might be delayed due to the sandbox effect.
The most effective strategy for link building is to create high-quality, valuable content that naturally draws backlinks from other reputable sites. The next best approach is to engage in outreach campaigns, building relationships with industry influencers and websites to secure backlinks through valuable contributions like guest blogs. Additionally, leveraging internal links to distribute link equity across your site can significantly enhance the ranking of key pages.
Conduct regular audits of your site to identify and address thin or duplicate content by enhancing or removing such pages. Aim to drive more successful clicks across a broader set of queries and create more link diversity. Implementing these strategies can also aid recovery from the Helpful Content Update if your site was affected.
Concentrate your strategy on developing comprehensive content around specific themes to establish authority. Incorporate relevant keywords naturally within your content to signal topic relevance. Additionally, develop a robust internal linking structure to connect related content and strengthen the topical focus.
Regularly refresh your content. Enhance it with unique information, new images, videos, etc.
By frequently updating a page, allowing it to be crawled, and repeating this process, you can phase out older versions. Given that historical versions carry varying weights and scores, this approach can be advantageous.
Place your target keywords at the beginning of the page title.
Ensure that key pages within your site link to important content to boost their prominence. Include links to significant pages from your homepage and other high-traffic pages to enhance their scores. Make it easy for users to find and navigate to crucial pages from various points within your site. This can increase the OnSiteProminence score, thereby improving their visibility and ranking potential on Google.
Specify a date and maintain consistency across structured data, page titles, and XML sitemaps.
Integrate local keywords and phrases that resonate with your target audience. Develop content that engages with local issues, events, and interests to connect with your regional audience. Also, securing citations and backlinks from local directories and websites can strengthen your local authority.
Focus on creating content that emphasizes key entities relevant to your topics, enhancing normalized topicality and relevance scores. Ensure entities within your content are well-connected and contextually linked to improve their scores. Clearly identify authors and publishers to leverage their authority and boost content credibility.
Wrapping Up
The leaked Google Search API documents offer incredible insights into the intricate algorithms that determine search rankings. Factors such as site authority, click data, NavBoost, the sandbox effect, domain age, Chrome data, and various demotion signals are key to better search visibility.
By prioritizing high-quality content, adhering to ethical SEO practices, and optimizing for UX, you can effectively optimize for these confirmed Google ranking factors.

 About Growfusely
About Growfusely White LabelMake us your (hidden) helping hand in delivering high-quality work to your SaaS clients.
White LabelMake us your (hidden) helping hand in delivering high-quality work to your SaaS clients. TeamCheck out the faces (and their backstories) behind our brand.
TeamCheck out the faces (and their backstories) behind our brand. Partner With UsJoin forces with us and earn a recurring monthly commission.
Partner With UsJoin forces with us and earn a recurring monthly commission. Careers We're HiringJoin our growing team of passionate content marketing geeks.
Careers We're HiringJoin our growing team of passionate content marketing geeks. SEOBoost your search engine rankings with a blend of compelling content and technical tweaks.
SEOBoost your search engine rankings with a blend of compelling content and technical tweaks. Content MarketingFuel your brand awareness and user acquisition with strategic content creation and distribution.
Content MarketingFuel your brand awareness and user acquisition with strategic content creation and distribution. Link BuildingEarn relevant, high-quality backlinks from top websites in and around your niche.
Link BuildingEarn relevant, high-quality backlinks from top websites in and around your niche. Content WritingGet consistent, high-quality content that’s loved by users and search engines alike.
Content WritingGet consistent, high-quality content that’s loved by users and search engines alike. Creative ServicesLeverage our seasoned designers to create custom-branded lead magnets, landing pages, infographics, and more.
Creative ServicesLeverage our seasoned designers to create custom-branded lead magnets, landing pages, infographics, and more. Digital PRSecure strong brand mentions and links on high-authority niche publications.
Digital PRSecure strong brand mentions and links on high-authority niche publications. SaaS InfographicsLearn battle-tested best practices on all things SaaS marketing — visually.
SaaS InfographicsLearn battle-tested best practices on all things SaaS marketing — visually. SaaS InterviewsRead our tête-à-têtes with SaaS marketing experts on achieving content-driven organic growth.
SaaS InterviewsRead our tête-à-têtes with SaaS marketing experts on achieving content-driven organic growth.